GPU 管理概述¶
本文介绍 算丰 AI 算力容器管理平台对 GPU为代表的异构资源统一运维管理能力。
背景¶
随着 AI 应用、大模型、人工智能、自动驾驶等新兴技术的快速发展,企业面临着越来越多的计算密集型任务和数据处理需求。 以 CPU 为代表的传统计算架构已无法满足企业日益增长的计算需求。此时,以 GPU 为代表的异构计算因在处理大规模数据、进行复杂计算和实时图形渲染方面具有独特的优势被广泛应用。
与此同时,由于缺乏异构资源调度管理等方面的经验和专业的解决方案,导致了 GPU 设备的资源利用率极低,给企业带来了高昂的 AI 生产成本。 如何降本增效,提高 GPU 等异构资源的利用效率,成为了当前众多企业亟需跨越的一道难题。
GPU 能力介绍¶
算丰 AI 算力容器管理平台支持对 GPU、NPU 等异构资源进行统一调度和运维管理,充分释放 GPU 资源算力,加速企业 AI 等新兴应用发展。GPU 管理能力如下:
- 支持统一纳管 NVIDIA、华为昇腾、天数等国内外厂商的异构计算资源。
- 支持同一集群多卡异构调度,并支持集群 GPU 卡自动识别。
- 支持 NVIDIA GPU、vGPU、MIG 等 GPU 原生管理方案,并提供云原生能力。
- 支持单块物理卡切分给不同的租户使用,并支持对租户和容器使用 GPU 资源按照算力、显存进行 GPU 资源配额。
- 支持集群、节点、应用等多维度 GPU 资源监控,帮助运维人员管理 GPU 资源。
- 兼容 TensorFlow、pytorch 等多种训练框架。
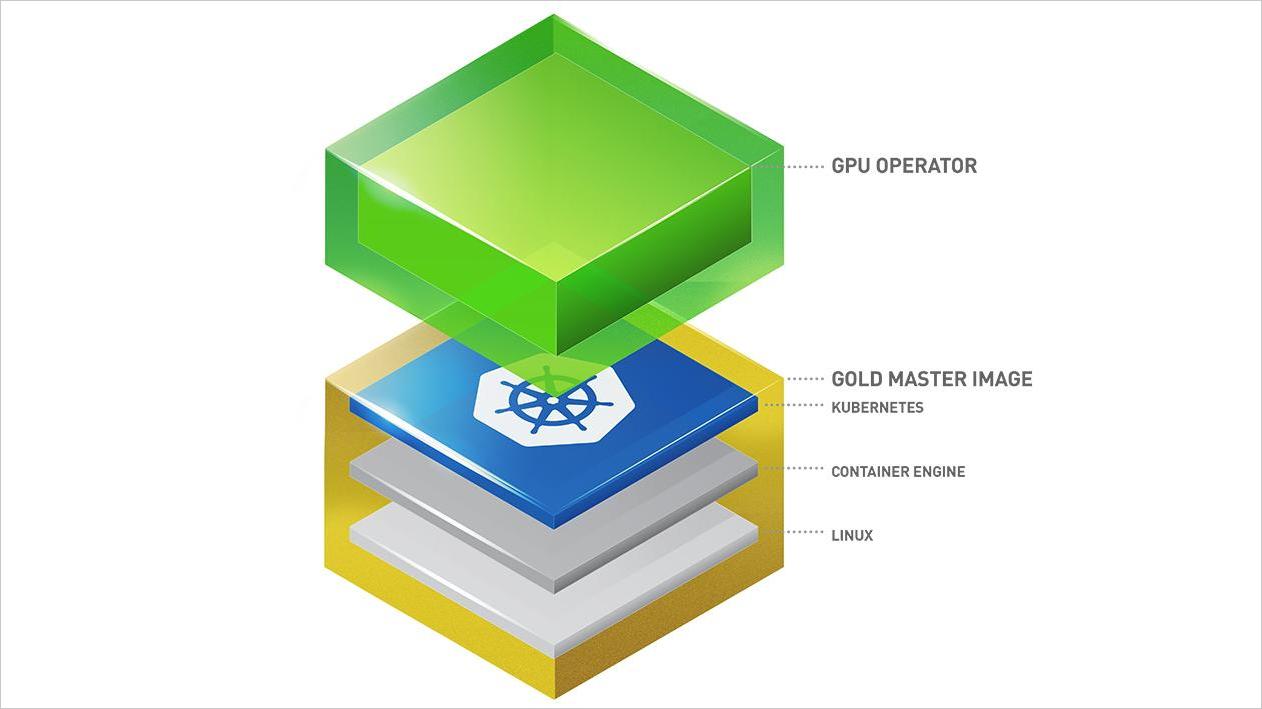
GPU Operator 介绍¶
同普通计算机硬件一样,NVIDIA GPU 卡作为物理硬件,必须安装 NVIDIA GPU 驱动后才能使用。 为了降低用户在 kuberneets 上使用 GPU 的成本,NVIDIA 官方提供了 NVIDIA GPU Operator 组件来管理使用 NVIDIA GPU 所依赖的各种组件。 这些组件包括 NVIDIA 驱动程序(用于启用 CUDA)、NVIDIA 容器运行时、GPU 节点标记、基于 DCGM 的监控等。 理论上来说用户只需要将 GPU 卡插在已经被 kubernetes 所纳管的计算设备上,然后通过 GPU Operator 就能使用 NVIDIA GPU 的所有能力了。 了解更多 NVIDIA GPU Operator 相关信息,请参考 NVIDIA 官方文档。 如何部署请参考 GPU Operator 离线安装
NVIDIA GPU Operator 架构图: